Shared_ptrНа предыдущей лекции была задана домашняя работа, в которой требовалось реализовать один из видов «умных» указателей – считающий (shared_ptr). Для этого требуется завести два класса: Shared_ptr и Storage. Мы знаем, что в большинстве случаев, согласно правилам инкапсуляции, поля классов следует делать private.
Как же можно организовать у методов класса Shared_ptr возможность доступа к полям класса Storage?
Первый вариант - создать внутри Storage public-методы, возвращающие значения private-полей. Однако в этом случае любой пользователь Shared_ptr сможет добраться до данных, хранящихся в нашем вспомогательном классе, что нехорошо. Соответственно ни конструктор, ни методы, ни любые другие члены класса Storage не моогут быть public. Так же не должно быть отдельного хедера, чтобы пользователь Shared_ptr не знал о существовании данного private класса Storage.
Есть и другой вариант решения возникшей проблемы. В С++ существует возможность разрешить доступ к закрытым членам класса Storage. Для этого нужно объявить класс Shared_ptr его «другом», используя ключевое слово friend.
class Storage {
private:
int myCounter;
Object *myPointer;
private:
Storage();
friend class Shared_ptr;
};
Теперь из класса Shared_ptr можно обращаться к любым private-членам класса Storage.
Так как оба класса находятся в одном хедере, то возникает следующая проблема. С одной стороны Shared_ptr использует поля и методы Storage:
class Shared_ptr{
...
//обращение к Storage
};
С другой стороны в Storage упоминается о существовании Shared_ptr:
class Storage {
...
friend class Shared_ptr;
};
Поэтому необходимо объявить класс Storage вначале заголовочного файла «Shared_ptr.h», просто дописав строчку:
class Storage;
Тогда внутри Shared_ptr мы сможем использовать поля уже объявленного класса Storage.
friend Ключевое слово friend можно использовать не только для объявления одного класса «другом» другого. Так же существуют отдельные «дружественные» методы. Например, мы могли написать следующее:
friend Shared_ptr::Shared_ptr(Object *p);
Следует отметить, что при таком использовании ключевого слова friend, в случае необходимости что-то поменять в одном методе, нам придется во второй так же вносить изменения. Это, безусловно, неудобно и требует дополнительной внимательности.
Класс Storage теперь закрыт от посторонних вмешательств. Однако при подключении хедера «Shared_ptr.h» пользователь не сможет использовать слово Storage, так как оно уже занято.
Для того чтобы не загромождать пространство имен, предлагается поместить класс Storage внутрь класса Shared_ptr.
class Shared_ptr {
private:
class Storage {
... //члены класса Storage
friend class Shared_ptr;
};
... //члены класса Shared_ptr
};
Теперь члены класса Storage будут называться по-другому. Например, конструктор выглядит следующим образом:
Shared_ptr::Storage::Storage(){
...
}
Как мы уже знаем, в стандартной библиотеке существует множество полезных классов. Например, std::string и std::list. Для того чтобы ими пользоваться, необходимо подключить соответствующие заголовочные файлы:
#include <string> #include <list>Обратим внимание на то, что названия хедеров не содержат расширения
«.h» (в С например существует «string.h», но этот файл совершенно не связан с std::string). printf и контейнер std::list одновременно. Для этого необходимо подключить следующие заголовочные файлы:
#include <stdio.h> #include <list>В целях повышения у написанного кода современности и эстетичности, в С++ существует хедер
<cstdio>. Работает он также как аналогичный <stdio.h> в С.
#include <сstdio> #include <list>
std::list и итераторыВ стандартной библиотеке, как уже говорилось ранее, существуют контейнеры std::list и std::vector. С одной стороны они чем-то похожи, например, у обоих классов существуют аналогичные методы push_back, pop_front и другие. С другой стороны, для std::vector возможно прямое обращение к i-му элементу (vector[i]), а для std::list никакого похожего метода нет.
Таким образом мы умеем заполнять список:
std::list <int> l; l.push_back(1); l.push_back(2); l.push_back(5);Но что же можно сделать, чтобы, например, вывести все элементы списка?
// вывод содержимого списка на экран
for (std::list<int>::iterator it = l.begin(); it != l.end(); ++it) {
printf(“%d\n”, *it);
}
В классе std::list есть вложенный подкласс iterator, для которого перегружены operator + и operator *. Таким образом, операция ++it передвигает итератор на следующий элемент списка, а *it – возвращает то, на что указывает итератор.
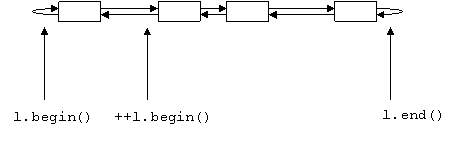
Методы l.begin() и l.end() возвращают итератор, указывающий на начало и конец списка соответственно. Так как адрес данного элемента есть адрес точки начала памяти, отведенной под него, то фактически итератор указывает на место между элементами.
*l.begin() – это содержимое первого элемента.
++ l.begin() указывает на следующий после первого элемент списка, то есть на второй.
Следует заметить, что операция *l.end() – осмысленного значения не имеет, так как пытается обратиться к содержимому еще несуществующего элемента.
Рассмотрим что происходит при пред- и постинкрементации:
++it - возвращает *this, предварительно передвинув итератор на 1.it++ - перемещается к следующему объекту в списке и возвращает объект, который был текущим перед перемещением. То есть копируется старое значение итератора, производится инкрементация, возвращается запомненное значение.
Получается, что перегруженный оператор it++ работает дольше, чем ++it.
Вывод: по возможности использовать более быструю прединкрементацию ++it.
std::vector и итераторыКак говорилось ранее, std::list и std::vector чем-то похожи. Так, у класса вектор тоже есть подкласс iterator, с которым можно работать аналогичным образом.
std::vector <int> v;
for (std::vector<int>::iterator it = v.begin(); it != v.end(); ++it) {
printf(“%d\n”, *it);
}
Может оказаться полезным воспользоваться спецификатором typedef, и упростить объявление новых переменных типа std::vector<int>.
typedef std::vector<int> intVector;
intVector v;
for (intVector::iterator it = v.begin(); it != v.end(); ++it) {
printf(“%d\n”, *it);
}
Теперь для перехода от структуры vector к list нужно поменять лишь строчку typedef-объявления.
1) Необязательно думать, какую структуру использовать.
2) Можем перебирать элементы структуры циклом for.
3) Можем вставлять элемент a на место, куда указывает итератор it, методом l.insert(it, a).
4) Удалять элемент, на который указывает итератор it, методом l.erase(it).
Как мы знаем структура vector реализована с помощью расширяющегося массива. Представим себе ситуацию, когда имеющийся массив из 10 элементов целиком использован, и нам необходимо добавить в него еще один элемент.
v.insert(it, 11);Программа, для увеличения размера вектора, скорее всего организует новый массив в другой части памяти. Так как итератору никак эта информация не передается, то он по-прежнему будет указывать на старый массив. Получается, что в процессе добавления нового элемента итератор может стать некорректным. А значит необходимо каждый раз обновлять значение итератора, чтобы он указывал на актуальный элемент структуры.
it = v.insert(it, 11);
(reverse_iterator).
for (std::list<int>::reverse_iterator it = l.rbegin(); it != l.rend(); ++it) {
printf(“%d\n”, *it);
}
Операция * всегда возвращает элемент, который стоит перед элементом, на который указывает обратный итератор.
Поэтому эти два выражения эквивалентны: reverse_iterator(v.end()) и v.rbegin().
Отличия от обычного итератора:
Инкрементация (+1) передвигает итератор в обратную сторону
если it = l.end(), то *it теперь имеет смысл - это последний элемент
const std::list<int>; const_iterator it;
Существуют и другие виды итераторов.
setРаботу итераторов мы обсуждали на примере классов std::list и std::vector. Безусловно, итераторы существуют и в любых других коллекциях.
Рассмотрим контейнер set, в котором можно хранить множество - набор уникальных элементов, отсортированных в определенном порядке.
std::set<int> s;Для множества s например определен метод
find. Он возвращает итератор, указывающий на i-й элемент или на s.end(), если искомый не найден.
std::set<int>::iterator it = s.find(20);
if (it != s.end()) {
//20-й элемент существует
}
mapВ map хранится множество упорядоченных пар - ключ и значение (Key, Value). Соответственно итератором можно эти пары просматривать.
std::map<std::string, std::string>::iterator it; it->first; // ключ объекта, на который указывает it (Key) it->second; // значение объекта (Value) (*it); // объект специального типа std::pair<const Key, Value>