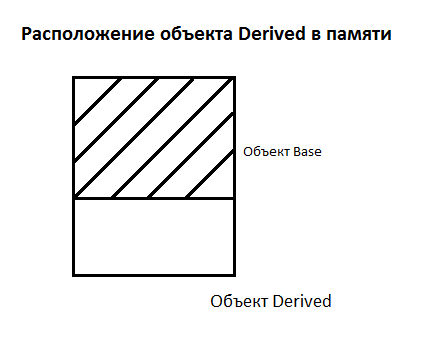
Наследование
1. Конструкторы
Конструктор по умолчанию
Предположим, у нас есть базовый класс Base и унаследованный от него класс Derived.
Видно, что он объект класса Derived содержит внутри себя объект класса Base.
Для того, чтобы создать объект Derived, нужно сначала создать Base.
new Derived(); // отвести место в памяти под объект Derived и вызвать его конструктор
Рассмотрим реализацию конструкторов классов Base и Derived
(далее по тексту определение некоторых конструкторов и деструкторов, а также методов классов написаны внутри
определений классов исключительно для удобства, реально их нужно писать в .cpp-файлах):
class Base {
Base() {
printf("Base constructor\n");
}
};
class Derived : public Base {
Derived() {
printf("Derived constructor\n");
}
};
После этого в результате выполнения строчки
new Derived();
будет выведено
Base constructor
Derived constructor
В скомпилированном коде внутри конструктора Derived будет вызван конструктор Base.
Таким образом, важно запомнить следующие вещи:
1) При создании объекта класса-наследника вызывается конструктор наследуемого им класса
2) Код конструктора базового класса вставляется в начало конструктора суперкласса.
Отсутствие конструктора по умолчанию у базового класса
Предположим, что в классе Base нет конструктора по умолчанию − например, класс определен следующим образом:
class Base {
Base(int param) {
printf("Base constructor\n");
}
};
В таком случае код
Base b;
не скомпилируется.
Можно явно указать, какой конструктор вызывать в Derived у Base:
class Derived : public Base {
Derived();
};
// Определение конструктора Derived
Derived::Derived() : Base(42) {
printf("Derived constructor\n");
}
Здесь будет вызван конструктор Base с параметром 42.
Еще один пример:
class Derived : public Base {
Derived(int param);
};
// Определение конструктора Derived
Derived::Derived(int param) {
printf("Derived constructor\n");
}
перед конструктором Derived компилятор попробует вызывать конструктор Base по умолчанию
(несмотря на то, что вызывать конструктор Base с параметром param кажется весьма естественным),
что повлечет за собой ошибку компиляции.
Кроме того, передаваемые конструктору суперкласса параметры можно использовать для вызова конструктором базовых классов:
Derived::Derived(int param) : Base(param) {
printf("Derived constructor\n");
}
Продолжение примера с переводчиком
Теперь вспомним о примере структуры наследуемых классов, приведенной в предыдущей лекции:
Классу Translator неплохо бы иметь поля myFrom и myTo с тем, чтобы уметь отвечать, с какого языка на какой они могут переводить.
Для этого рассмотрим следующую реализацию этого класса:
class Translator {
private:
const Language myFrom, myTo;
public:
Translator(const Language &from, const Language &to) : myFrom(from), myTo(to) {
}
Нелишним будет отметить, что инициализировать константные поля класса Translator: myFrom и myTo можно только в этом месте,
в инициализации конструктора.
Тогда реализации конструктора класса TranslatorEnXX будет выглядеть следующим образом:
TranslatorEnXX::TranslatorEnXX(const Language &to) : Translator("English", to) {
}
, а конструктора TranslatorEnRu так:
TranslatorEnRu::TranslatorEnRu() : TranslatorEnXX("Russian") {
}
Примечание Здесь Language представляет собой некий класс, имеющий конструктор от const char *.
2. Права доступа при наследовании
Описание модификаторов прав доступа
private-члены доступны лишь внутри своих классов, и в наследниках недоступны.
В языке C++ доступны три типа модификаторов прав доступа к элементам класса (полям, методам, конструкторам и деструктору):
, и всегда, когда доступны private, доступны protected и public, и всегда, когда доступны
protected, доступны public.
Право доступа protected означает «разрешить доступ мне и всем моим наследникам (а также их наследникам и т.д.)».
Возвращаясь к примеру с переводчиком
C учетом этого будет разумно переписать определение класса Translator следующим образом:
class Translator {
private:
const Language myFrom, myTo;
protected:
Translator(const Language &from, const Language &to) : myFrom(from), myTo(to) {
}
};
с тем, чтобы запретить код вроде этого:
new Translator("English", "Russian");
Вообще говоря, можно использовать protected-поля, но это не рекомендуется из-за того, что их изменение достаточно сложно отследить.
Права доступа для виртуальных методов
Рассмотрим классы Translator и TranslatorFrRu:
class Translator {
<модификатор прав доступа 1>
virtual std::string translate(const std::string &text) = 0;
};
class TranslatorFrRu : public Translator {
<модификатор прав доступа 2>
std::string translate(const std::string &text);
};
Далее в коде
Translator *t = new TranslatorFrRu();
t->translate(text);
в месте вызова метода translate для t компилятором будут проверены права доступа для класса Translator, потому что
t объявлена в виде Translator *t.
Поэтому в месте <модификатор прав доступа 1> неминуемо должно быть написано «public», иначе код не скомпилируется.
В скомпилированном коде на языке C++ прав доступа нет.
Поэтому в месте <модификатор прав доступа 2> может быть любой модификатор.
Но для того, чтобы предупредить нежелательное пользование классами вроде следующего:
Translator *tFr = new TranslatorFrRu();
t->translate(text);
разумно поставить на место <модификатор прав доступа 2> private.
Примечание Например, в языке Java код компилируется в байт-код, исполняемый Java-машиной, и там права доступа проверяются в момент исполнения кода. Поэтому в случае с языком Java на месте <модификатор прав доступа 2> должно было стоять слово public. Исторически язык C++ был создан как один из быстро работающих языков, а всякое лишнее действие во время исполнения влечет за собой некоторую потерю эффективности, поэтому в момент работы программы никаких проверок прав доступа не происходит.
3. Закрытое (private) наследование
Различия между закрытым (private) и открытым (public) наследованием
class Base {
public:
void foo();
};
class Derived : <модификатор наследования> Base {
};
На место <модификатор наследования> можно поставить одно из слов private, public,
а также ничего не поставить.
Рассмотрим случай, когда сюда поставили private вместо public. Напомним, что раньше можно было писать так:
Base *p = new Derived;
, поскольку класс Derived − наследник класса Base. Но теперь этот код перестанет компилироваться с ошибкой «объект типа Derived не принадлежит Base», а код
Derived d;
d.foo();
с ошибкой «метод foo класса Derived − private».
Пример применения
Пример Предположим, что нам нужно реализовать стек на базе массива (std::vector) или списка (std::list).
Рассмотрим следующую реализацию:
class Stack : private std::list {
public:
void push(int value) {
push_bask(value);
}
int pop() {
int temp = back();
pop_back();
return back();
}
};
, а также такую:
class Stack : private std::list {
private:
std::list myList;
...
};
Никаких содержательных различий между этими двумя способами нет. Приведенный выше пример − почти единственный пример применения private-наследования.
Поэтому почти никакого смысла в private-наследовании нет.
Случай, когда вместо <модификатор наследования> не указано ничего, эквивалентен указанию там private.
Факты
1. struct и class
В языке C++ struct − почти синоним слова class.
В аккуратно написанном коде вида
class A {
private:
...
public:
...
};
struct A {
private:
...
public:
...
};
разницы между таким классом и структурой нет. Различие между словами class и struct
лишь в том, что для элементов класса, для которых не указаны права доступа,
по умолчанию используются права private, а для структуры − public.
То же касается и модификаторов наследования:
// Эти 2 строчки эквивалентны
class A : B
class A : private B
// Эти 2 строчки эквивалентны
struct A : B
struct A : public B
С точки зрения компилятора разницы между class и struct нет.
С психологической точки зрения struct представляет собой некую маленькую структуру, а class − большой объект, поэтому
struct обычно не наследуют (хотя это возможно).
Пример использования struct:
struct Point {
double x;
double y;
};
drawSegment(Point p0, Point p1); // Удобно передавать пару точек, а не четыре координаты
2. О перечисляемом типе enum
В приведенном выше примере с переводчиками у нас присутствовал класс Language, который лишь обозначал язык.
Ясно, что создавать для такой цели класс несколько неразумно. Рассмотрим решения данной проблемы:
Решение №0 (define-ы)
#define ENGLISH 0
#define RUSSIAN 1
#define FRENCH 2
Таким образом, мы назначаем каждому языку соответствующее число, и при каждом появлении в коде слова «ENGLISH»
препроцессор заменит его на 0.
У такого решения есть следующие минусы:
Решение №1 (константы)
Мы можем определить следующие константы:
const int ENGLISH = 0;
const int RUSSIAN = 1;
Так нельзя писать в хедере (из-за возможных ошибок линковки, когда два .cpp-файла используют данный хедер, эти константы скомпилируются
в объектные модули каждого из этих файлов, а далее произойдет ошибка линковки).
Поэтому в хедере нужно писать объявление констант (объявление переменных, вообще говоря, пишется аналогично):
foo.h
extern const int ENGLISH; // Объявление
foo.cpp
#include "foo.h"
const int ENGLISH = 0; // Определение
У такого решения тоже есть минусы:
Решение №2 (enum)
enum Language {
ENGLISH,
RUSSIAN,
};
Мы определили перечисляемый тип Language.
Примечание В последней строчке может как стоять запятая, так и не стоять.
Использование определенного типа Language:
Language lang;
lang = ENGLISH;
Видно, что перечисляемый тип загромождает пространство имен своими константами, но обычно он помещается внутрь класса или namespace'a, например:
class Translator {
public:
enum Language {
ENGLISH,
RUSSIAN
};
...
};
Тогда обращаться к нему, а также его элементам придется так:
Translator::Language
Translator::ENGLISH
О связи между перечисляемым типом и int
int l = ENGLISH; // так можно
LANGUAGE lang;
lang = 10; // так нельзя (перечисляемый тип − не число), не скомпилируется
lang = (Language)10; // так можно (явным образом указываем компилятору, что понимаем, что делаем)
Вообще говоря, перечисляемый тип представляет из себя int (целое число), но во избежание ошибок явно присваивать переменной перечисляемого типа целое значения запрещено (третья строчка).
Но с помощью явного приведения типов это возможно (последняя строчка), так мы показываем компилятору, что понимает, что делаем и снимаем с него ответственность за дальнейшее.
Кроме того, первый элемент перечисляемого типа будет храниться в памяти как число «0», второй − как «1» и т.д.