

ООП: реализация и основные идеи.
Создание объектов и их наследников. Процесс компиляции.
Рассказанное ниже в точности верно для С++ и практически совпадает тем, что происходит в Java. Рассмотрим пример.
public class Base {
int myI;
foo() {
...
}
bar() {
...
}
final zzz() {
...
}
}
public class Derived extends Base {
int myJ;
foo() {
...
}
xxx() {
...
}
}
Посмотрим, что происходит, когда мы пишем b = new Base();
При вызове функции у объекта, например, b.foo(), нужна информация, что этот объект именно типа Base, а не типа Derived. Возможное решение - можно было бы поместить в объект адреса функций, но с увеличением их числа размер объекта тоже будет расти, а это плохо (см. рисунок).
myI
|
|
| адрес foo() адрес bar() адрес newFunction(…) |
К тому же, если все-таки хранить эти адреса, то они дублируются во всех объектах типа Base.
Выход – хранить в объекте всего один указатель на таблицу виртуальных функций (см.рисунок).
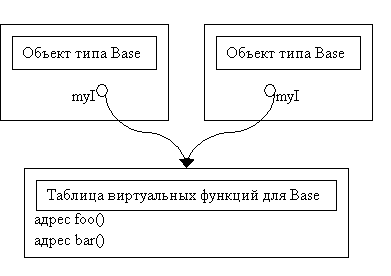
Посмотрим, что происходит, когда мы пишем b = new Derived();
Рассмотрим рисунок.
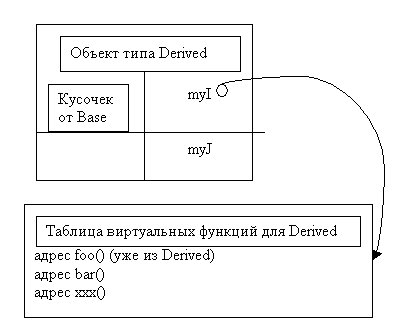
Когда я вызываю функцию foo() у объекта типа Base или Derived,
b.foo();
это скомпилируется в байт-код, который будет делать следующее:
- Сначала нужно залезть в объект
- Взять оттуда первые 4 байта – это адрес виртуальной таблицы для объекта.
- Найти в этой виртуальной таблице адрес
foo(), перейти по нему и вызватьfoo().
Вызов final метода у объекта, т.е. метода, который никогда не будет перекрыт, нужно рассмотреть отдельно. У объекта типа Base есть такой метод zzz(). В таблице виртуальных функций нет ссылки на zzz(). Когда этот метод вызывается, то он сразу скомпилируется в байт-код с адресом zzz, который и вызовет ее.
Такой способ вызова функций называется статическим связыванием. Можно сделать вывод, что динамическое связывание менее эффективное, чем статическое. Динамическое связывание дольше и невыгоднее.
Если теперь у наших классов будут определены какие-то конструкторы:
public class Base {
Base() {
foo();
}
foo() {
System.out.println(1);
}
}
public class Derived extends Base {
int myValue = 2;
Derived() {
foo();
}
foo() {
System.out.println(myValue);
}
}
Когда мы напишем new Derived(), что выведется на экран?
Сначала выполнится конструктор Base, потом конструктор Derived – и строк будет две. Во второй строке при выполнении конструктора Derived будет напечатана 2, а в первой? Ответ на этот вопрос - для каждого языка по-разному. В Java указатель на таблицу виртуальных функций в объекте – это указатель на окончательную таблицу виртуальных функций, т.е. на таблицу для Derived. И в момент вызова функции foo() у Base, которая уже перекрыта в Derived, значение myValue еще не инициализировано 2, но по умолчанию оно 0, поэтому выведется 0. Возникает опасность – в конструкторе вызывается виртуальная функция, а объект не достроен!
Вывод – использовать в конструкторе виртуальные функции – это плохая идея!
Наследование классов
В Java у всех классов, кроме одного, есть предок. Если при объявлении класса extends не написано, то неявно этот класс наследуется от класса Object. У самого Object предка нет.
public class ComplexInteger extends Object
эквивалентно
public class ComplexInteger
Все методы класса Object виртуальны. Например,
public String toString() //возвращает строку из названия класса и адреса объекта. public boolean equals(Object o) //метод проверки на равенство объектов.
Эти методы можно переопределять.
Не нужно путать два понятия – overriding и overloading.
Overriding – это перекрытие метода, т.е. в наследуемом классе мы перекроем метод с таким же названием и таким же набором типов параметров.
Overloading – это перегрузка метода, т.е. напишем метод с таким же названием, но с другим набором параметров (они могут различаться либо типом, либо количеством).
Пример overloading - метод println(…), который определен для:
- 1 для строк
- 1 для объектов
- 8 для примитивных типов
- 1 без параметров
Стандартный метод equals выглядит так:
public boolean equals(Object o){
return this == o;
}
То есть он просто проверяет две ссылки – указывают ли они на один и тот же объект. Рассмотрим на примере класса комплексных числе, как можно сравнить два объекта.
ComplexInteger ci0 = new ComplexInteger();
ComplexInteger ci1 = new ComplexInteger();
//первый вариант – используем метод equals
if (ci0.equals(ci1)) {
...
}
//второй вариант
if (ci0 == ci1) {
...
}
Различия между первым и вторым способом:
- Первый способ дороже – потому что для него надо вызвать метод.
- Если ссылка на
ci0 == null, то при использовании первого способа все сломается, а второй сработает, поэтому, вообще говоря, первый способ хуже.
Но тогда не понятно, какая польза от метода equals.
Польза возникает, если этот метод перекрывать. Перекроем его для нашего класса комплексных чисел.
public class ComplexInteger{
public boolean equals(Object o){
//тип возвращаемого значения и модификатор доступа обязательно такие, параметром должен быть Object
//первая попытка
return ((myIm == o.myIm) && (myRe == o.myRe));
//Но! У объекта o нет полей myRe и myIm. Перепишем по-другому.
//вторая попытка
ComplexInteger ci = (ComplexInteger) o;
return ((myIm == o.myIm) && (myRe == o.myRe));
}
}
Теперь поля есть. Польза от этого метода в том, что два объекта равны не только тогда, когда равны их ссылки, но и тогда, когда у них одинаковые вещественная и комплесная части.
Но! Есть опасность, что в качестве параметра я передам не ComplexInteger. Это надо проверять – и без этого не обойтись. Для этого есть специальный оператор instanceof. Заметим, что делать так - очень плохо с точки зрения ООП.
Напишем почти правильно:
public boolean equals(Object o) {
if(!(o instanceof ComplexInteger)) {
return false;
}
ComplexInteger ci = (ComplexInteger) o;
return ((myIm == o.myIm) && (myRe == o.myRe));
}
Но если ссылки все-таки равны, то нет смысла выполнять дорогостоящую операцию приведения типа – проще сразу проверить на равенство ссылок. Это дешево на фоне остального кода метода, но если повезет, то мы много выиграем! Теперь итоговый вариант:
public boolean equals(Object o) {
if (this == o){
return true;
}
if(!(o instanceof ComplexInteger)) {
return false;
}
ComplexInteger ci = (ComplexInteger) o;
return ((myIm == o.myIm) && (myRe == o.myRe));
}
Разделение логики структур данных и логики вычислений. Идеология ООП.
Рассмотрим уже написанный нами односвязный список и посмотрим на его метод вычисления суммы элементов.
public class List {
private ListElement myHead;
public int sum (){
int sum = 0;
for (ListElement i = myHead; i != null; i = i.myNext) {
sum += i.getValue();
}
return sum;
}
}
public class ListElement {
private int myValue;
private ListElement myNext;
}
Эта реализация метода вычисления суммы элементов плоха по следующим причинам:
- функция вычисления суммы элементов списка практически совпадает с функцией вычисления длины списка, произведения элементов и т. п. – то есть придется каждый раз переписывать практически один и тот же код. Но ведь обычно его не переписывают, а копируют, и в процессе копирования можно забыть что-либо исправить. Такую ошибку найти уже очень трудно.
- эта функция противоречит идеологии ООП.
Поясним вторую причину.
Если мне вдруг потребуется еще какая-нибудь другая функция, я полезу исправлять список. Велик риск того, что где-то я забуду исправить что-либо, или подпорчу случайно какие-то уже отлаженные на предыдущем исправлении методы, и такие ошибки найти уже будет очень сложно. Идея ООП состоит в том, что
Объекты нужны для того, чтобы разделить программу на куски и каждый кусок может быть написан и отлажен по отдельности.
Теперь напишем правильный метод с точки зрения ООП.
Первый вариант.
Завожу класс (права доступа нас пока не интересуют)
public class Summator {
int calculate(List list) {
int sum = 0;
for (ListElement i = list.myHead; i != null; i = i.myNext) {
sum += i.myValue;
}
return sum;
}
}
Это гораздо более объектно-ориентированный способ.
Раньше для вызова метода приходилось писать
list.sum();
А теперь –
new Summator().calculate(list);
Только пользы пока от этого исправления нет. Будем исправлять дальше.
Напишем промежуточный вариант - выделим код вычисления в отдельный метод, чтобы его легко можно было заменить, не испортив всего остального.
Второй вариант.
public class Summator {
int mySum;
int calculate(List list) {
mySum = 0;
for (ListElement i = list.myHead; i != null; i = i.myNext) {
processElement(i);
}
}
int result() {
return mySum;
}
void processElement(ListElement e) {
mySum += e.myValue;
}
}
Мы убрали недостаток, что функция вычисления суммы элементов списка - внутренняя функция для List. Теперь нам нужно завести отдельный класс для вычисления суммы элементов, который будет переопределять метод processElement(ListElement e).
Третий вариант.
public class ListProcessor {
int myResult;
int calculate(List list) {
myResult = 0;
for (ListElement i = list.myHead; i != null; i = i.myNext) {
processElement(i);
}
}
int result() {
return myResult;
}
void processElement(ListElement e) {
}
}
class Summator extends ListProcessor {
void processElement(ListElement e) {
myResult += e.myValue;
}
}
Теперь надо писать
ListProcessor s = new Summator(); s.calculate(list); return s.result();
Польза – мы избавились от многократного использования цикла for – потому что убрали многократное повторение кода в разных методов. В данном случае цикл простенький, но он вполне может быть очень хитрым и трудоемким (например, обход какого-нибудь графа).
Теперь я могу написать еще один класс для вычисления длины списка. Он будет практически такой же, за исключением метода processElement(ListElement e) – переменную myResult будем увеличивать на 1. Но вот с произведением все не так здорово – из-за того, что у нас начальное значение myResult = 0, произведение посчитать не получится.
Выход – можно написать метод initialValue(), который нужно перекрывать каждый раз и устанавливать в нем соответствующее задаче значение myResult.
Основная польза от такого подхода – это то, что мы разделили логику обхода (структур данных) и логику вычислений.
Абстрактные классы.
Метод, который мы только что написали, меня опять не устраивает, потому что есть проблема -
пустое тело метода processElement(ListElement e) – можно случайно забыть его перекрыть. А без него Summator не имеет никакого смысла!
Можно сделать так, чтобы этот метод не просто можно было перекрывать, а его нужно было перекрывать. Для этого сделаем метод processElement(...) абстрактным:
abstract void processElement(ListElement e);
Теперь мы обязаны его перекрыть, иначе это ошибка времени компиляции.
Только класс ListProcessor тоже нужно сделать абстрактным
abstract public class ListProcessor {
...
}
Метод initialValue() теперь тоже лучше сделать абстрактным:
abstract initialValue();
Тогда в наследуемом классе мы его перекрываем:
int initialValue() {
return 0;
}
У абстрактного класса могут быть не абстрактные методы, но абстрактные методы могут быть только у абстрактного класса!
Рассмотрим 2 рисунка – 2 иерархии объектов. Пустые квадратики означают абстрактные классы, закрашенные квадратики означают, что у них есть instance. Разберемся, какая из иерархий хорошая, а какая плохая. На практике instance есть только у листьев дерева. Поэтому иерархия слева – это хороший стиль, и, соответственно, иерархия справа – плохой стиль.
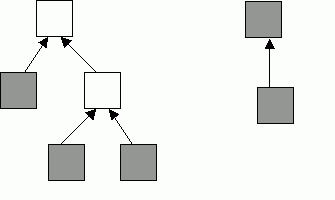
Итак, вторая проблема решена. Теперь хотим решить первую проблему.
Избавимся от метода calculate(...). Теперь сумма будет считаться так:
List list = ... list.calculate(new Summator());
Метод calculate(...) перетаскиваем в List. А в классе ListProcessor вместо abstract initialValue() напишем более общий метод abstract int initialize(), который мы также будем перекрывать.
public class List {
...
int calculate(ListProcessor lp) {
initialize();
for (ListElement i = list.myHead; i != null; i = i.myNext) {
lp.processElement(i);
}
return lp.result();
}
}
abstract public class ListProcessor0 extends ListProcessor {
public int initialize() {
return myResult = 0;
}
}
public class Summator extends ListProcessor0 {
public void processElement(int value) {
myResult += value;
}
}