
Классы и объекты
Отступление о целочисленных типах
Типы и их размеры
Рассмотрим некоторые целочисленные типы в языке С:
| Тип | Размер |
char |
1 байт |
int |
"естественный" |
short |
sizeof(short) <= sizeof(int) |
long |
sizeof(long) >= sizeof(int) |
char* |
"естественный" |
Для типов int и char* в графе Размер указано "естественный", но это не значит, что у
этих типов всегда одинаковый размер.
К int относятся целые числа, обычно соответствующие естественному размеру целых в используемой машине. Размер указателя зависит от того,
сколько ячеек памяти мы можем адресовать.
К примеру, на 32-битной архитектуре мы умеем адресовывать 232 ячеек памяти, на 64-битной - 264.
При этом, на машине с 64-битной архитектурой переменная типа int занимает 32 бита, а char* - 64 бита.
Дополнительные целочисленные типы
Когда мы обсуждаем какой-либо язык программирования, мы обсуждаем две вещи:
Язык (ключевые слова)
Стандартная библиотека (набор функций, которые предоставлены в скомпилированном виде)
Если взять старые языки, например, Pascal, то в его стандартной библиотеке мы найдём довольно мало функций. Со временем, размеры синтаксиса увеличивались не так сильно, в отличие от стандартной библиотеки. Стандартная библиотека языка С составляет пару десятков заголовочных файлов, а в языке Java она насчитывает уже несколько тысяч файлов.
Одним из ключевых слов языка С является typedef. С его помощью мы можем писать свои собственные типы.
Например, если мы привыкли к языку Pascal и хотим писать привычное нам integer, а не int, то мы можем создать новый тип:
typedef int integer;
Помимо функций, в стандартной библиотеке определены и некоторые типы, например:
ptrdiff_tЭто целочисленный тип. Он имеет знак и его размер такой же, как у указателя. Тип
ptrdiff_tобычно применяется для счетчиков циклов, индексации массивов, хранения размеров, адресной арифметики. В ряде случаев использование типаptrdiff_tбезопаснее и эффективнее, чем использование более привычного программисту типаint. Кстати, результат выражения, где один указатель вычитается из другого(ptr1-ptr2), как раз будет иметь типptrdiff_t.size_tЭтот тип является целочисленным беззнаковым, его размер так же совпадает с размером указателя. Результат операции
sizeofимеет типsize_t. То есть, это "то, в чём можно измерять размер памяти". Его также применяют для счетчиков циклов, индексации массивов, хранения размеров и адресной арифметики.На самом деле, функция
mallocобъявлена так:void *malloc(size_t size);
Таким образом, при вызове функции
malloc(-1), память не будет выделена, поскольку её не хватит для этого действия.
Классы и объекты
Недостатки нашего типа Array
Допустим, мы создали массив и теперь хотим создать ещё один такой же массив:
{
Array a(25);
Array b = a;
...
}
Когда мы инициализировали массив b таким способом, его поле mySize стало равным 25, а myData стало
указывать на ту же часть памяти, что и a.myData. Если сначала был вызван конструктор для массива a, а потом
для b, то деструкторы будут вызваны в обратном порядке. Проблема заключается в том, что деструктор b освободит память, а
деструктор a будет пытаться освободить память, которую уже освободили.
Ещё с одной проблемой мы можем столкнуться, когда попытаемся скопировать массив в уже существующий:
{
Array a(25);
Array c(36);
c = a;
...
}
В этом случае произойдёт утечка памяти, поскольку мы изменим указатель c.myData.
Решение проблем
- Конструктор копирования
Разберёмся сначала с первой проблемой. При создании копии вызывается конструктор, но он отличается от того, что мы писали раньше. Мы объявляли его таким образом:
Array(size_t size);
У каждого класса есть конструктор вида
Array(Array &array);
Он называется конструктором копирования. Его можно создать вручную, иначе он автоматически создаётся компилятором. По умолчанию, он копирует все поля:
Array(Array &array){ mySize = array.mySize; myData = array.myData; }Нашу проблему можно решить двумя способами. Один из них состоит в том, чтобы при создании копии выделять кусок памяти, и в него копировать массив. Для этого напишем сами конструктор копирования:
Array(Array &array){ mySize = array.mySize; myData = new int[mySize]; for (int i = 0; i < mySize; ++i){ myData[i] = array.myData[i]; } }Второе решение заключается в том, чтобы запретить писать
Array b = a;. Для этого нужно объявить конструктор копирования какprivate.Как уже было сказано, если не писать конструктор копирования самим, то он создастся автоматически, а если объявить его в хедере следующим образом:
... public: Array(Array &array); ...
и не написать его определение, то в момент сборки произойдёт ошибка.
Полезное использование ссылок
Рассмотрим некоторую функцию, у которой в качестве параметра выступает массив:
{ Array a(25); sum(a); }При вызове функции
sum(a)вызовется конструктор копирования, чтобы положить переменную на стек. Копирование объекта работает долго, поэтому не следует писать так:int sum(Array a){ ... }Лучше писать таким образом:
int sum(Array &a){ ... }Если объявить конструктор копирования как
private, то если мы будем описывать функциюsumпервым способом, то будет ошибка: нельзя использовать конструктор копирования. Это способ не забывать писать&. - Оператор присваивания
Пусть конструктор копирования запрещён (то есть объявлен как
private). Но копировать следующим образом нам никто не мешает:{ Array a(25); Array c(36); c = a ... }Оператор присваивания тоже можно написать самим, иначе он создаётся автоматически. Объявляется он так:
void operator =(Array &array);
Равносильны записиc.operator=(a);иc = a;Поскольку оператор присваивания по умолчанию создаётся автоматически, то для решения проблемы следует объявить его как
private. Теперь нельзя писатьc = a;. Если мы пишем оператор присваивания сами, то мы должны в его определении сделать следующие действия:-
Освободить память, на которую указывает
myData -
Скопировать
mySize -
Создать новый массив
-
Скопировать массив
Оператор присваивания будет определён так:
void operator =(Array &array){ delete[] myData; mySize = array.mySize; myData = new int[mySize]; for (int i = 0; i < mySize; ++i){ myData[i] = array.myData[i]; } }В этом коде есть ошибка: мы не учли возможность присваивания
a = a. В этом случае после присваивания в массиве будут лежать какие-то непредсказуемые значения. Рассмотрим такое присваивание на примере массиваА, состоящего из двух целочисленных элементов (10и20):Проблема появится после освобождения памяти, на которую указывает
A.myData. Прежние значения элементов будут утеряны. При создании нового массива элементам будут присвоены какие-то значения. Соответственно, после выполнения первых трёх действий массив будет выглядеть так: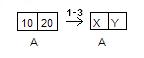
где Х и У - какие-то целочисленные значения.
Последним действием мы скопируем все элементы, отчего массив не изменится.
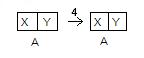
Результат присваивания не такой, как мы ожидали. Нам следовало вначале проверить объекты на равенство:
0. Если это тот же объект, то ничего не делать
Правильное определение оператора присваивания выглядит так:
void operator =(Array &array){ if (&array == this){ return; } delete[] myData; mySize = array.mySize; myData = new int[mySize]; for (int i = 0; i < mySize; ++i){ myData[i] = array.myData[i]; } }Мы использовали ещё одно ключевое слово -
Заметим, что оператор присваивания "содержит" конструктор копирования.this. Это указатель на самого себя.Возвращаемое значение оператора присваивания
В языке С можно писать так:
if (a = 0){ ... }или
int a, b, c; a = b = c;
Получается, что оператор присваивания имеет возвращаемое значение. Мы тоже хотим иметь право писать так:
Array a(25), b(36), c(49); a = b = c;
Если скобки не расставлены, то подразумеваетсяa = (b = c).Оператор присваивания будет определён следующим образом:
Array &operator =(Array &array){ if (&array == this){ return *this; } delete[] myData; mySize = array.mySize; myData = new int[mySize]; for (int i = 0; i < mySize; ++i){ myData[i] = array.myData[i]; } return *this; } -